本文章仅供稿于知乎、UWA和我个人网页,未经允许禁止转载。
大家好,我是舒航,现任职于心动网络,主要负责RO的优化工作。今天主要想和大家分享一下,我这段时间在Lua性能优化方面的一些经验。
现在市面上大部分Unity游戏都能支持热更,主要热更Lua和一些资源。而Lua主要实现一些UI界面之类的非核心逻辑,这样虽然Lua这部分代码非常灵活,增加功能、修复BUG都非常方便。但是由于Lua实现的大部分都是UI,那么lua热更出去的功能最多就是一些新UI界面罢了,或者用资源配合配置表来扩充下游戏既有内容。如果想做个特殊的玩法势必受到掣肘,一般最后都会发现导出的接口不全,非得打整包才行。为了使得RO的玩法更灵活,热更的游戏内容更丰富,其实就是为了满足策划们的各种需求啦,RO战斗逻辑的主体都是在Lua中完成。所以RO相对于其他的游戏,对Lua代码的性能要求会更高一些。
在我对Lua代码进行性能优化的时候,主要分为两部分:
- 内存优化
- 常驻内存优化
- 内存分配优化
- 内存泄露优化
- CPU优化
这篇文章主要是和大家分享第一点,在内存优化上的一些经验和手段。在我进行Lua优化之前,我们已经请过UWA团队进行过专业的诊断了,而且收效很好,在此给UWA团队赞一个。那么,面对一个已经进行过一次彻底优化的项目,要进行更深入的优化之前首先要问自己一个问题:
我为什么能比前人优化得更彻底,做到前人没有做到得事情呢?
总的来说就是两点:
- 工具更先进
- 项目更熟悉
所以在这样的策略下,我主要是针对我们的项目编写了两个工具,LuaMemoryMonitor和LuaProfiler。一个用于优化内存泄露和内存分布,一个用于优化内存分配。有了更好的工具之后,再针对性地优化自己项目的代码,无论是效率还是结果都非常好。LuaMemoryMonitor能在十几分钟内就定位到泄露的代码,用这个工具我们一下午就查清了战斗中的内存泄露,并且能清晰地列出Lua的内存分布。而LuaProfiler帮助我们把Lua内存分配速度降低到了原来的40-50%。
LuaMemoryMonitor
LuaMemoryMonitor主要由两部分组成:
C库Snapshot
UnityEditor
一、 C库的实现细节
C库的主要工作有:
快照_G
计算Lua对象内存大小
- 储存快照
1. 快照_G
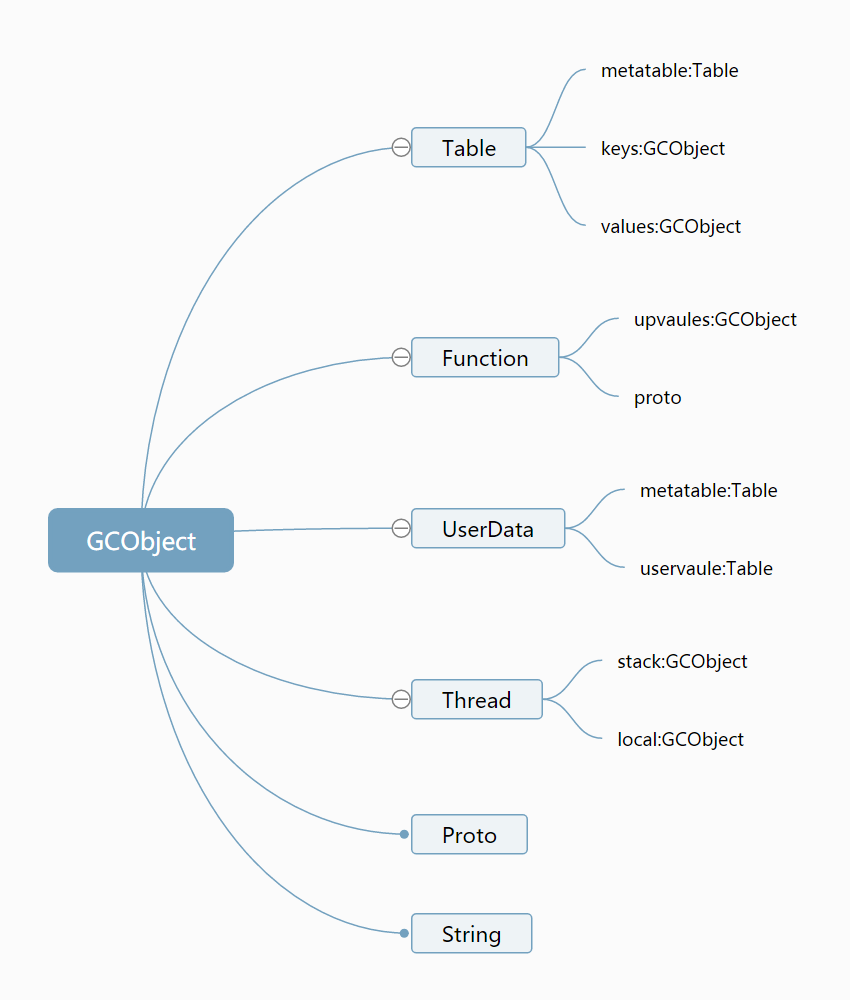
Lua中可回收的对象递归关系如图:
遍历_G时按以下的结构进行遍历,只需要编写5个函数traverse_object、traverse_table、traverse_function、traverse_userdata、traverse_thread,然后从traverse_table(_G)开始递归即可。在统计内存大小时,即要统计对象本身占用的内存,也要递归地遍历它所引用的所有对象占用的内存。其中string是Lua内部管理的,统计时要注意同一字符串的不同引用不能重复统计内存。
有兴趣的详见Lua源码lgc.c
propagatemark函数
2. 计算Lua对象内存大小
对Lua当前内存进行快照时,我主要是快照_G,如果有需要的话可以快照Registry。如果仅仅是查内存泄露,那么不统计_G内每一Entry的内存大小也可以。但是我为了分析内存分布,那么必须得统计每一Entry的内存大小。统计Lua对象的内存大小是没有现成的接口的,我这里给大家提供一种思路,也是Lua源码中统计对象内存大小的办法。例如一个Table占用的内存大小为:
size = sizeof(Table) + sizeof(TValue) * h->sizearray +
sizeof(Node) * (isdummy(h) ? 0 : sizenode(h));
//还要加上Table引用的所有GCObject
size = size + sizeof(metatble) + sizeof(keys) + sizeof(values);
3. 储存快照
由于要对Lua内存进行分析,那么就不能把快照又存到Lua内,这样很容易干扰自己的数据采集。这也是把快照的代码写在C里的一个重要原因,如果是在Lua里写的话,就必须要小心翼翼地处理这些数据了。而写在C里就很好解决了,我在C里用一颗多节点树来储存每一个快照,多个快照组成一个链表。
二、 UnityEditor
1. Editor特性
Snapshot库已经为编辑器准备好了所有数据了,现在只需要想一个好主意、好方法来利用这些数据。这里我做了一个特别的功能,可以很高效地利用这些数据。在UnityEditor里可以对每个快照进行逻辑操作。
- 求交集
- 即两个或多个快照中都存在的对象,即这些快照中的常驻内存。
- 求补集
- A在B中的补集指在A中但不在B中的对象,即A相对于B的增量。
简单例子:在刚进入战斗时采样得到A快照,战斗一段时间后采样得到B快照,离开战斗场景回到主城,手动GC后采样得到C快照。求AB的补集得到一个新的快照D,D即是战斗期间新增的内存。求AC的补集得到快照E,E即是 战斗期间新增并且离开战斗GC后没有释放掉的内存 。对D和E求交集,得到快照F,F即是战斗中新增但是回到主城后释放掉的内存。这其中E中的对象非常有可能就是泄露了的内存,而F中的对象是可以尝试更早地释放的内存。这时可以选中E快照,把E快照输出到Editor上,输出为一个树状结构,就像Unity自带的Profiler中一样,如果有泄露的话基本上就无所遁形了。而直接输出A快照的话,就能得到刚进入战斗时的内存分布。
三、 常见泄漏:C#代理
我们项目中查到的比较多的泄露就是C#代理了,如果把Lua匿名函数注册给C#的代理,那么这个Lua匿名函数将不能正确地被LuaGC了,也就是泄露了。改进方法就是不把Lua匿名函数注册给C#代理,这样的话,每隔一段时间C#都会主动Dispose。
四、 其他内存优化:常驻内存优化
常驻内存方面我们一直控制的很好,这次我们主要是优化了大量的table配置表,这个优化主要参考了UWA中的这篇文章Lua配置表存储优化方案——卢建。
五、 LuaMemoryMonitor改进
现在LuaMemoryMonitor定位是一个快速定位泄露的工具,还需要提前知道疑似泄露的地方,然后有针对地采样。有一个改进方法是,在Lua中写一个定期检查内存疑似泄露的工具,然后在疑似泄露的地方用LuaMemoryMonitor进行快速定位。
LuaProfiler
解决了常驻内存和内存泄露的麻烦后,发现内存增长的很快,很短时间内就会到达我们项目设置的阈值,迎来一次GC。而刚GC完空余出来的内存又会迅速地被分配出去,内存长时间处于高位。频繁分配内存不仅降低了性能,还使手机更容易发热了。为了定位和优化内存的高分配,我模仿Unity的Profiler写了一个LuaProfiler,并做了相应的扩展。这个工具也由两部分组成:
C库
UnityEditor
一、 LuaProfiler的C库
LuaProfiler的C库主要完成了数据采集的工作。它在Lua虚拟机中注册了钩子函数,每次Lua Call 和 Return 的时候都会触发回调。在每次回调的时候,在C里维护了一颗 限制层级的多节点树 ,由C#主动来取这颗树。每帧都取每帧都清空,即是逐帧统计。每隔一段时间取,但不清空,即是累计模式。
二、 LuaProfiler的UnityEditor
Editor的主体是一组递归绘制的foldout控件,在Editor上显示出一个树状结构。LuaProfiler能实时地根据调用层级,然后通过各个按钮实现各种规则排序。这和UnityProfiler相同,想必大家不会陌生。另外LuaProfiler不仅提供了和UnityProfiler一样的逐帧模式,还提供了统计模式和累计模式。在累计模式下,会把每一帧的内存分配累加起来,以树状结构的方式展示出来。而统计模式则是把每一个函数的内存分配累加起来,以Top10的形式展现出来。统计模式不关心调用层级,只关心所有函数中哪些函数分配的内存最多。在这样一个工具的帮助下,RO的内存分配优化变得格外简单、高效。
三、 常见优化:string.gsub和string.gmatch
在我们项目中,用这两个string库函数完成了一个计算中文个数、长度的工具函数。但是容易被忽略的是,string.gsub和string.gmatch会产生大量的子串,这些子串都会开辟一片内存,而我们根本用不上这些子串。我发现函数1在很多项目中都普遍存在,但是用函数2会更好一些。
function getTextLen(str)
local result = 0
for uchar in string.gmatch(str, "[%z\1-\127\194-\244][\128-\191*") do
result = result + 1
end
return result
end
function getTextLen(str)
local byteLen = #str
local strLen = 0
local i = 1
local curByte
local count = 1
while i <= byteLen do
curByte = string.byte(str, i)
count = 1
if curByte > 0 and curByte <= 127 then
count = 1
elseif curByte >= 192 and curByte < 223 then
count = 2
elseif curByte >= 224 and curByte < 239 then
count = 3
elseif curByte >= 240 and curByte < 247 then
count = 4
end
i = i + count
strLen = strLen + 1
end
return strLen
end
四、 常见优化:Lua中string是不可变值
这一点也经常被大家忘记,哪怕是写Lua的老手。在以下代码中,因为Lua的string是不可变值,每次拼接都会产生一串新的字符串。第6行会产生”仙境”、”仙境传”、”仙境传说”一共3串字符串,但是我们只是需要第三串而已(“仙”字被Lua背部重用了)。这无形中就多开辟了一部分内存,我们可以对以下代码进行优化,从而避免浪费。这种疏忽经常出现在 I/O文件、聊天频道、处理配置描述字段时发生。
1 local tab = { "R", "O", "仙", "境", "传", "说" }
2
3 function getName()
4 local ret = ""
5 for i = 3, #tab do
6 ret = ret .. tab[i]
7 end
8 return ret
9 end
10
11 function getName()
12 return table.concat(tab, 3, #tab)
13 end
五、 常见优化:内存池
如果想降低内存分配速度,使用内存池复用对象是必不可少的。在Lua内存池的使用过程中,最容易出现的问题是,忘了放回池子以及池子大小不合理。
总结
全文上下,用到的技术都不难,相信大家都能搞定。在这里主要是和大家分享一下拿到原始数据后,如何处理过滤数据、信息的经验,从而更快更准确地定位问题。如果大家有更好更精准的处理数据、过滤信息的方法请不吝赐教。
- 邮箱 inkiu0@gmail.com
- QQ 286553528
- UWA群内ID ink_U0
预告
下一次将会给大家带来LuaProfiler的CPU优化部分,在这部分内容主要有:
- 用多线程缓解DeepProfile数造成的卡顿
- Lua的CPU时间优化经验
- Lua的CPU时间到底消耗在哪一块,Lua是不是不堪大任呢?